
Maintaing State on Kubernetes
technical kubernetes hyperledger openshift programming caching infinispan jboss datagridMaintaining State when deploying Application on Kubernetes
Overview
Linux containers should be disposable (or emepheral is a more technical term). Meaning that a container should be treated as an immutable software asset which includes the base operating system, software libraries (required dependencies), configuration, folders, and the application itself.
This immutable nature requires that no data is stored within the container1.
How do you maintain state
A key advantage of containerising application is that the image (template for the container) that was tested in QA is guaranteed to have the same behaviour in production environment. So to maintain state (store data) with a containerised application, we can employ three (3) patterns:
- Caching
- Persistent Volumes
- External storage
Caching
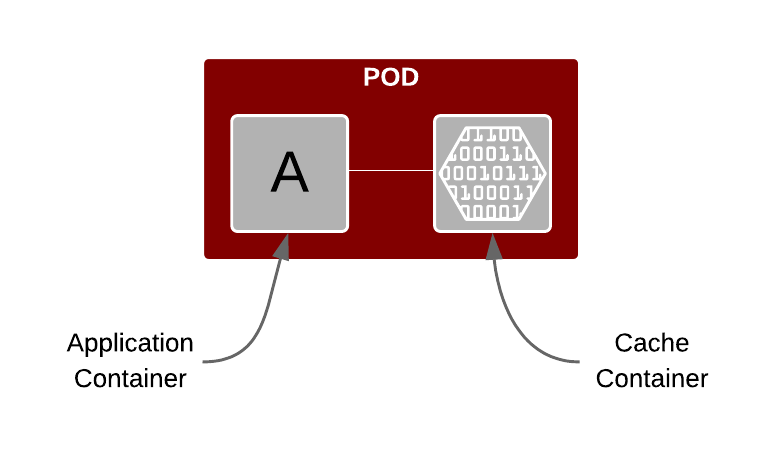
The diagram above gives a highlevel view of a POD with an application container and a caching container. The idea is to cache relevant information into the container providing caching capability.
Scaling the application is as simple as scaling the POD and it will automatically scale the cache. Point to note is that the cache is native to the specific application container running in the same POD as the application container itself.
In many scenarios, it might make more sense to externalise caching sub-system and lifecycle manage it, independently of the application container. Diagram below gives us a highlevel view of what that pattern would look like.
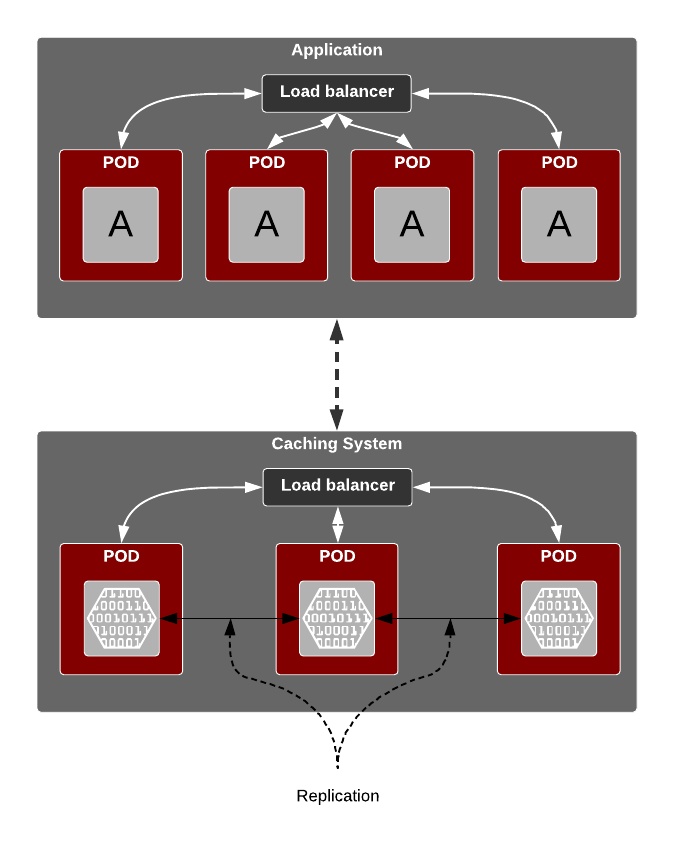
Persistence of Cache
Persisting data held within a cachee might be desirable for reasons like:
- Memory is volatile, so a cache store could increase the durability of the information
- Write-through as an mechanism to use cache as a layer between an application and external storage subsystem
- To retain hot data (frequently used) data in memory, and passivate less frequently used data to a backend store
Caching systems like Infinispan offer sophisticated capabilities like cache store, chaining of cache store, cache passivation, cache loaders, etc.
- Cache store: Persistence allows configuring external stores based on filesystem, JDBC, JPA, RocksDB, LevelDB, custom store.
- Write-through: this strategy allows information to be persisted in one or more caching stores synchronously. As an example an invocation of
cache.put()will not return until update is reflected in the caches store(s). - Write-behind: updates to the cache are asynchronously written to the cache store. Normally, this means that updates to the cache store are done by a separate thread to the client thread interacting with the cache.
For further details on persistence and Infinispan in particular, refer to this user guide.
Persistent volumes
Managing storage is a distinct problem from managing compute resources. Kubernetes persistent volume (PV) framework to allows administrators to provision persistent storage for a cluster. Using persistent volume claims (PVCs), developers can request PV resources without having specific knowledge of the underlying storage infrastructure.
It is important to understand the relationship between PODs, PVCs and PV. In simple terms, a POD uses PVC to bind to the underlying PV. Once a this binding is established, that PV is exclusively assigned to the requesting PVC. Meaning that only one PVC is bound to a PV.
But note that multiple PODs can claim reference to the same PVC, which would refer to a single PV.
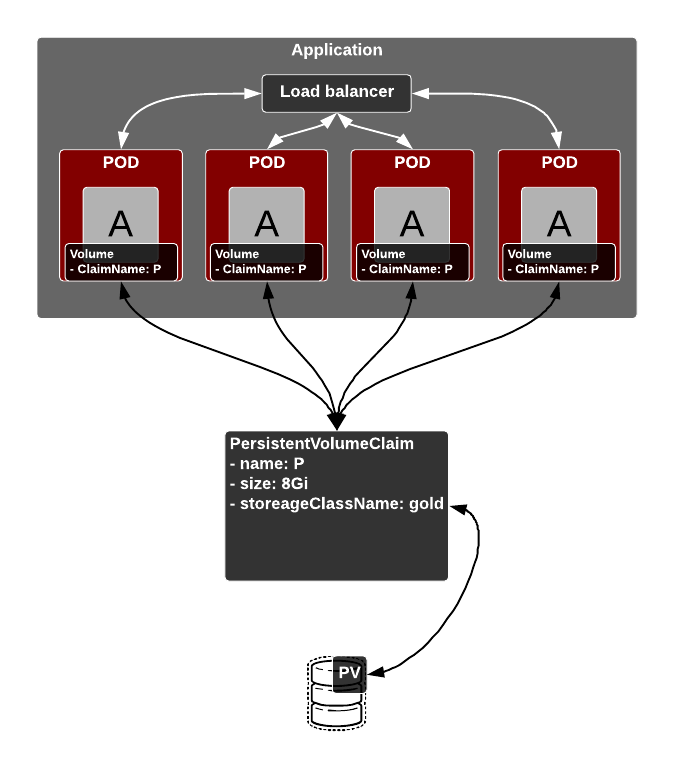
For further details on lifecycle of PV and PVC, please refer to the Kubernetes storage manual.
Access Modes
Three types of acces modes available for PersistentVolume are (as long as they are supported by underlying resource provider):
- ReadWriteOnce – the volume can be mounted as read-write by a single node
- ReadOnlyMany – the volume can be mounted read-only by many nodes
- ReadWriteMany – the volume can be mounted as read-write by many nodes
External storage
This pattern employs an external data store. Meaning that the information resides in a database (or any data store), which is hosted outside the Kubernetes platform. Typically this will be provided as a database as a service. So that any application or a service residing in a POD on the Kubernetes cluster will simply access the database service to store or retrieve data at rest.
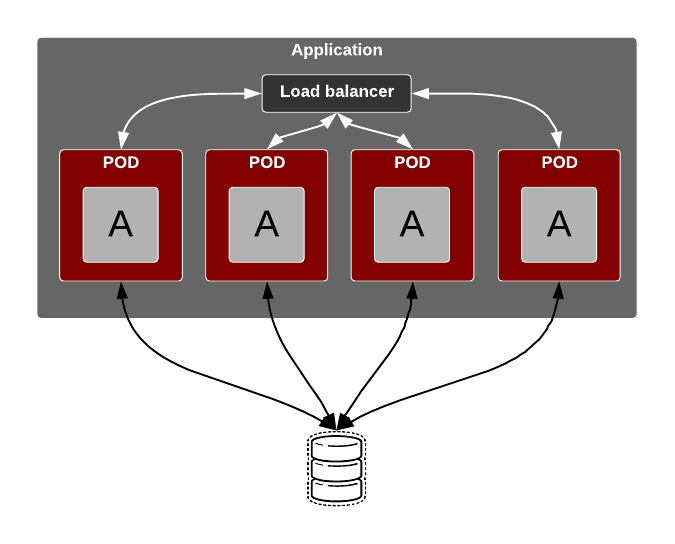
Maintaining state across Kubernetes cluster
Cache
Remote cache store configuration allows storing information in a remote cache cluster. This can be an interesting configuration for persistence across regions.
Persistent Volumes
Below is a list of commonly used types of persistent volumes. Majority of these provide a native data replication capability.
- NFS
- HostPath
- GlusterFS
- Ceph RBD
- OpenStack Cinder
- AWS Elastic Block Store (EBS)
- GCE Persistent Disk
- iSCSI
- Fibre Channel
- Azure Disk
- Azure File
- VMWare vSphere
- Local
External Storage
Majority of the external storage systems offer a native replication mechanism. Few examples: